2022. 5. 9. 20:34ㆍ자료구조와 알고리즘
학습목표
● 자료구조에 대해서 이해하고 적절하게 사용할 수 있다.
● 기초 알고리즘을 이해하고 적절하게 사용할 수 있다.
● 알고리즘은 분석할 수 있다.
● 프로그래밍 능력을 증진시킨다.
재귀
재귀는 함수가 자신을 호출하는것을 의미함.
재귀함수 : 자기 자신을 호출하는 함수. '분할 정복(divide & conquer)' 방식 문제에 따라 전체를 한 번에 해결하기보다 같은 유형의 하위 작업으로 분할하여 작은 문제부터 해결하는 방법이 효율적*일 수 있기 때문이다.
잘못된 재귀함수 -> 스택 오버플로
재귀의 구조는 중단시키는 기저 조건과 기저 조건을 수렴하게되는 재귀 조건으로 구성되어있음.
자료구조
자료구조는 크게 선형 구조와 비선형 구조로 나누어 진다.
선형 구조에는 리스트,스택,큐가 있다.
비선형 구조에는 그래프와 트리가 있다.
자료구조는 4가지 기본 방법을 사용하며 이를 연산이라고 한다.
● 읽기 : 자료구조 내 특정 위치를 찾아보는 것
● 검색 : 자료구조 내 특정 값을 찾는것
● 삽입 : 자료구조 새로운 값을 추가하는 것
● 삭제 : 자료구조 내 특정 값을 삭제하는 것
자료구조를 구현하는 방법은 크게 2가지로 나뉜다.
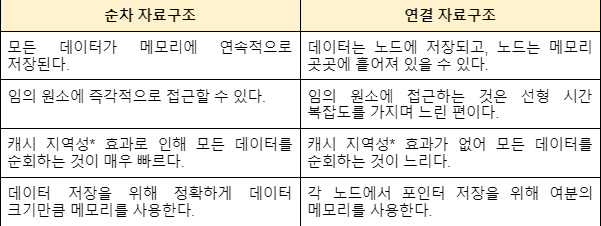
순차 자료구조(배열) : 구현할 자료들을 논리적인 순서대로 메모리에 연속하여 저장하는 구현 방식
연결 자료구조(포인터) : 노드라는 여러 개의 메모리 청크에 데이터를 저장하며, 이를 연결하여 하는 구현 방식
프로그래머는 둘의 특징을 명확히 알아서 조건과 사용빈도에 알맞게 하나를 선택하거나 두개를 조합해서 프로그램 개발을 하자.
알고리즘
알고리즘은 문제 해결 절차를 말함. 문제 해결에는 여러가지가 있고, 이중에서 최선을 선택해야한다. 그러므로 알고리즘을 분석하고 비교할줄 알아야 하며 알고리즘의 자원의 사용량을 분석해서 최대한 적게 사용할수록 효율적인 알고리즘이라고 한다.
시간 복잡도
하드웨어와 소프트웨어 환경을 배제한 객관적인 지표. 예를 들어 실행 시간을 분석하는거 같다.
알고리즘을 수행하는 데 필요한 연산이 몇 번 실행되는지 숫자로 표기한다.
연산이 몇개가 필요한가 <- 이게 중요함



입력값이 작을 때는 그차이가 크지 않았지만, 입력값이 점점 커질 수록 엄청나게 차이가 벌어진다.
그러니 알고리즘을 잘이용해 최대한 용량을 적게 쓰고 알고리즘을 효율적으로 구현하도록 고민해야한다.
Big-O 표기법
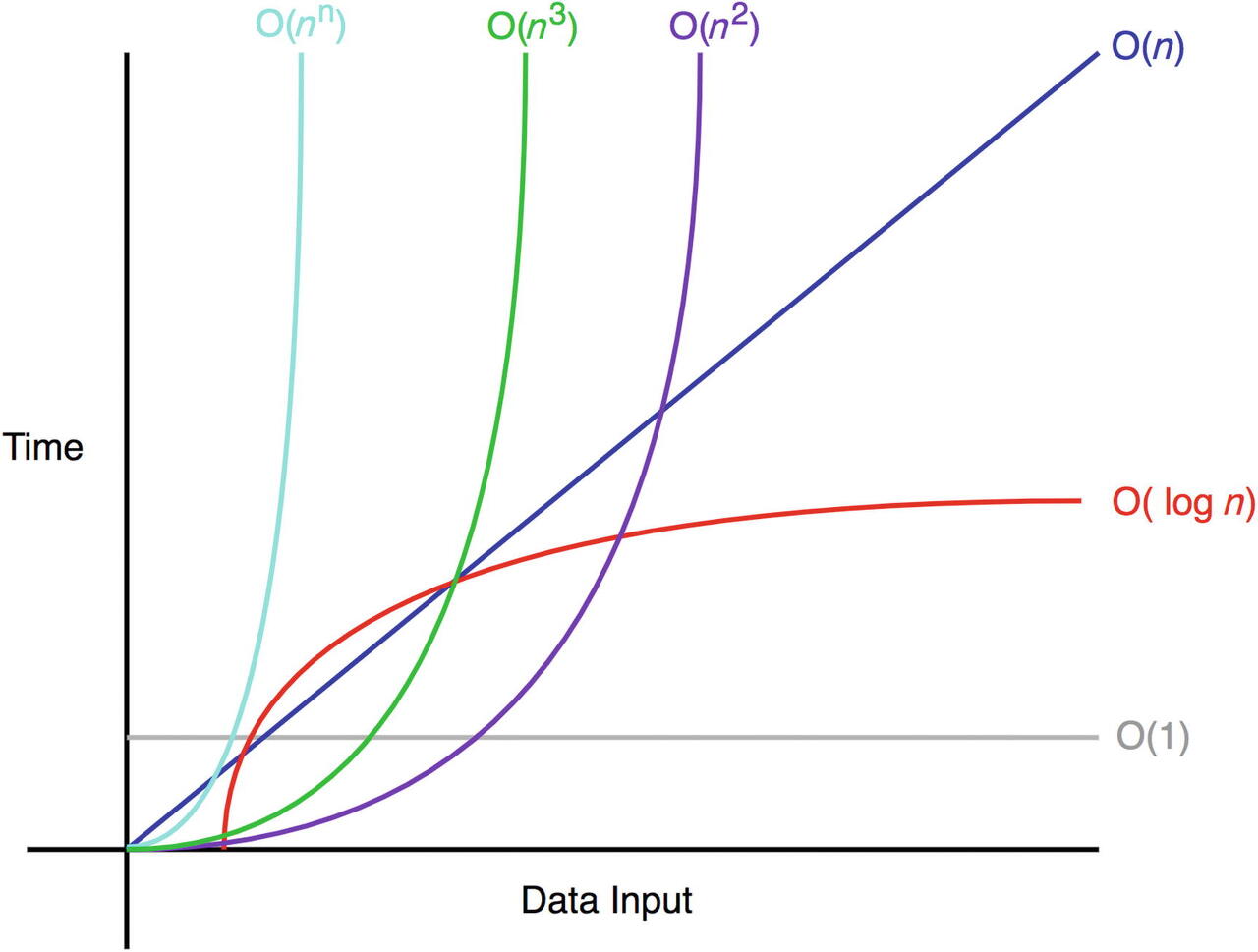
앞의 결과값을 다시 한번 관찰해보자. 다항식의 시간 복잡도 함수에서 입력값이 커져감에 따라 각 항의 결과값에 관여하는 정도가 달라지게 됨
O(1)<O(logn)<O(n)<O(nlogn)<O(n2)<O(n3)<O(2n)<O(n!) <- 카테고리는 이렇게 나누지만 항상 빠른게 아니다!!
유의할점!!
한 알고리즘이 다른 알고리즘보다 실제로 빠르다고 하더라도 같은 방식으로 표현이 될 수도 있다.
같은 카테고리라면 어떤 알고리즘이 더 빠른지 면밀한 분석이 필요하다.
가장최악일때 쓴다. 마지막방법
공간 복잡도
공간 복잡도는 알고리즘을 수행하는데 필요한 자원 공간의 양
시간 복잡도 vs 공간 복잡도
여태까지 배운 내용을 토대로 정리하자면 효율적인 알고리즘은 실행 시간이 적게 걸리며, 자원을 적게 소모하는 것이라고 할 수 있다. 하지만 시간과 공간은 반비례적인 경향이 있어 보통 알고리즘의 척도는 시간 복잡도를 위주로 판단한다. 즉, 시간 복잡도를 위해 공간 복잡도를 희생하는 경우가 많다.
시간\
STL
대부분의 언어는 기본 자료구조와 알고리즘을 제공하고 있다. c++의 경우는 표준 템플릿 라이브러리(Standard Template Library) 3가지로 구성되어있다.
- 임의 타입의 객체를 보관할 수 있는 구현체 컨테이너 (container)Library
- 컨테이너에 보관된 원소에 접근할 수 있는 포인터 반복자 (iterator)Library
- 반복자를 가지고 일련의 작업을 수행하는 알고리즘 (algorithm)Library
리스트
리스트는 순서를 갖고 있는 자료구조다. 순차 자료구조엔 선형 리스트, 연결자료구조엔 단일 연결 리스트,원형 연결 리스트 ,이중연결 리스트
선형 리스트와 연결리스트를 정확히 알아서 써야한다.
선형 리스트
순서 리스트라고도 하며. 임의 접근이 가능하다는 특징이 가지고 연속적으로 생기고 데이터 크기만큼 들어가 스택이 천천히 쌓인다.
임의 접근이 가능하다. 연속적이다.
주소연산이 가능한이유는 메모리가 연속적으로 할당되어있기 때문이다.임의 접근은 첫시작주소만 알면 데이터크기를 이용해 주소연산을 하여 원하는값을 임의접근이 가능하다.
연산
- 읽기
선형 리스트는 임의 접근이 가능하기 때문에 O(1)의 시간이 걸린다.
- 검색
하나하나 원소를 비교해가야 하므로 O(n)의 시간이 걸린다. 정렬되어 있다면 이진 검색을 사용할 수 있으며 이 경우 O(logn)이다.
- 삽입
원소를 어디에 삽입하냐에 따라 시간이 달라진다. 맨 끝에 데이터를 추가할 경우 O(1)이지만, 처음이나 중간이라면 모든 데이터를 이동해야 하기에 O(n)이 걸린다.
- 삭제
삽입과 마찬가지로 원소를 어디에서 삭제하냐에 따라 시간이 달라진다. 맨 끝의 데이터를 삭제할 경우 O(1)이지만, 처음이나 중간이라면 모든 데이터를 이동해야 하기에 O(n)이 걸린다.
이진 검색
이진 검색(binary search)은 검색할 범위를 절반으로 줄여가며 검색하는 방법이다. 이진 검색은 정렬된 배열에서 사용할 수 있다. 아래는 C++로 구현한 이진 검색 코드다.
연산
연결 리스트
연결 리스트는 STL 상에서는 std::forward_list, std::list로 구현되어 있다. 선형 리스트와 다르게 임의 접근이 불가능하다.
연속적으로 할당이 안되어있고 서로 떨어져있다.
- 읽기
연결 리스트는 임의 접근이 불가능해 요소 하나하나를 탐색해야 하므로 O(n)(선형시간)의 시간이 걸린다. 하지만 처음과 끝이라면 구현에 따라 O(1)이 될 수 있다.
- 검색
하나하나 원소를 비교해가야 하므로 O(n)의 시간이 걸린다. 선형 리스트와 다르게 이진 검색을 사용할 수 없다.
- 삽입 == 손코딩테스트에서 많이나옴
원소를 어디에 삽입하냐에 따라 시간이 달라진다. 앞이나 뒤에 데이터를 추가할 경우 O(1)이지만, 중간이라면 해당 위치까지 검색해야 하기 때문에 O(n)이 걸린다. 정확히 내가 삽입하는 위치를 알면 O(1) 이므로 오래걸리지 않는다.
- 삭제 == 손코딩테스트에서 많이나옴
삽입과 마찬가지로 원소를 어디에서 삭제하냐에 따라 시간이 달라진다. 앞이나 뒤의 데이터를 삭제할 경우 O(1)이지만, 중간이라면 O(n)이 걸린다. 정확히 내가 삽입하는 위치를 알면 O(1) 이므로 오래걸리지 않는다.
스택
스택(stack)은 리스트의 일종으로 연산이 한 쪽 끝에서만 이뤄지는 자료구조다. 가장 나중에 들어간 것이 처음에 나온다고 하여 LIFO(Last-In First-Out)구조라고도 한다. 스택의 끝을 위(top), 스택의 시작을 밑(bottom)이라 한다. 괄호가 올바른지 검사 / 후위 표기식 / DFS 등에 사용될 수 있다. STL에서는 std::stack으로 구현되어 있다.
스택은 롤메자이를 생각하면 편하다. 메자이스택을 쌓을려면 천천히 해야한다. 스택도 비슷한 의미인거같고스택은 후입선출이다. 마지막 먼저 나간다.
큐
큐(queue)도 리스트의 일종으로 스택과 다르게 가장 처음에 들어간 데이터가 처음에 나오는 FIFO(First-In First-Out) 자료구조다. 삽입이 일어나는 쪽을 뒤(rear), 삭제가 일어나는 쪽을 앞(front)라고 한다. 프린트 큐 / CPU 스케줄링 / 데이터 버퍼 / BFS 등에 사용된다. STL에서는 std::queue, std::deque로 구현되어 있다.
스택과 다르게 선입선출 가장먼저들어간게 가장먼저 나온다.
그래프
선형 자료구조로는 표현할 수 없는 문제가 있다. 회사의 조직도와 같은 계층을 표현한다던가 인스타그램 친구 관계도를 표현하는 것처럼 말이다. 이번 챕터부터는 이런 비선형적 문제를 다룰 수 있는 자료구조에 대해서 배우게 된다.
그래프는 선형적이다,그래프는 라이브러리에 구현 X 직접만들어야함
그래프란?
그래프(graph)는 관계에 특화된 자료구조로 정점(vertex)과 간선(edge)으로 구성되어 있다. 각 정점은 고유하게 식별되는 객체이고, 간선은 정점 간의 관계를 표현한다.
종류
그래프의 종류에는 간선이 방향성을 가지는 지에 따라 방향 그래프(directed graph)와 무방향 그래프(undirected graph)로 구분할 수 있으며, 간선이 단순 연결 이상의 정보(이를 가중치라 한다.)를 가지는 가중치 그래프(weighted graph)*도 있다.

용어
그래프와 관련된 여러가지 용어가 있다. 먼저 간선으로 연결된 정점끼리는 인접(adjacent)하다고 하며, 해당 간선은 연결된 정점에 부속(incident)되어 있다고 한다. 정점에 부속되어 있는 간선의 수를 차수(degree)라고 하며 정점으로 들어오는 방향인지, 나가는 방향인지 구분해 진입 차수(in-degree), 진출 차수(out-degree)로 말할 수 있다.
한 정점에서 다른 정점까지 간선으로 연결된 정점을 순서대로 나열한 리스트를 경로(path)라 한다. 경로를 구성하는 간선 수를 경로 길이(path length)라 하며, 모두 다른 정점으로 구성된 경로를 단순 경로(simple path)라 한다. 단순 경로 중 경로의 시작 정점과 마지막 정점이 같은 경로를 사이클(cycle)이라 한다. 또, 경로가 있으면 정점끼리 연결*(connected) 되었다고 한다.
*모든 정점이 연결되어 있다면 연결 그래프(connected graph), 아니면 단절 그래프(disconnected graph)라 한다.
표현
그래프를 표현하는 방법에는 인접 행렬(adjacency matrix)과 인접 리스트(adjacency list)가 있다. 아래의 그래프를 각각 인접 행렬과 인접 리스트로 나타내본다.
인접 행렬로 표현하기
정점이 N개 있을 경우 N x N 크기의 2차원 배열로 그래프를 표현할 수 있다. 배열의 원소는 간선의 가중치를 나타내게 된다. 가령 edges[i][j] 는 정점 i 에서 j로 가는 간선을 나타낸 것이다. 2차원 배열을 사용하기 때문에 그래프에 간선이 적다면* 그만큼 메모리를 낭비하게 된다.
순회
한 정점에서 시작해 그래프에 있는 모든 정점을 한 번씩 방문하는 것을 그래프 순회(graph traversal) 또는 탐색(search)이라 한다. 이러한 방법에는 깊이 우선 탐색(depth first search)과 너비 우선 탐색(breadth first search)이 있다.
최단 경로
최단 경로(shortest path)는 가중치 그래프에서 두 정점을 연결하는 경로 중 가중치의 합이 최소인 경로를 말한다. 최단 경로를 구하기 위해 간선이 없다면 무한대 값으로 저장하며, 가중치가 음수여선 안된다. 최단 경로를 구하는 알고리즘에서는 다익스트라 알고리즘과 플로이드 알고리즘이 있다.
다익스트라 알고리즘
다익스트라 알고리즘(dijkstra algorithm)은 하나의 시작 정점에서 다른 정점까지의 최단 경로를 구하는 알고리즘으로 무방향 그래프, 방향 그래프 모두 적용 가능하다. 기본 원리는 시작 정점에서 가장 가까운 정점을 선택하여 추가하면서 추가된 모든 정점에 대한 최단 경로를 구해가는 과정이다. 아래의 그래프를 이용해 구현해보자.

A* 알고리즘
A* 알고리즘은 다익스트라 알고리즘을 확장한 최단 경로 알고리즘이다. 가중치를 계산할 때, 허용적 휴리스틱(admissible heuristic)*을 사용하게 되며, 휴리스틱이 0이라면 다익스트라 알고리즘과 정확히 일치한다. 휴리스틱으로는 맨하탄 거리, 유클리드 거리, 코사인 유사도 등이 쓰인다.
플로이드 알고리즘
플로이드(floyd) 알고리즘*은 모든 정점 사이의 최단 경로를 구하는 알고리즘이다. 기본 원리는 아래와 같다.
*이렇게 구한 경로를 k-최단 경로라고도 한다.
트리
트리(tree)는 그래프의 일종으로 계층형 자료구조(hierarchical data structure)다. 트리는 데이터가 저장된 노드(node)와 노드 간 관계를 표현하는 간선(edge)으로 구성된다. STL에서는 std::set / std::map / std::multiset / std::multimap 으로 구현이 되어 있다. 재귀적임,비효율적임
용어
트리에는 여러 가지 용어가 있다. 아래의 그림을 참고하자.

- 조상(ancestor) 노드 : 한 노드에서 간선을 따라 루트 노드까지 이르는 경로에 있는 모든 노드
- 자손(descendant) 노드 : 조상 노드의 반대
- 차수(degree) : 한 노드가 가지는 서브 트리의 수. 노드의 차수 중 최댓값을 트리의 차수라 한다.
- 내부(internal) 노드 : 단말 노드를 제외한 나머지 노드
- 포레스트(forest) : 트리의 집합
순회
트리에 대한 순회는 전위 순회(pre-order traversal) / 중위 순회(in-order traversal) / 후위 순회(post-order traversal) / 레벨 순회(level-order traversal)가 있다
이진 검색 트리
이진 검색 트리(binary search tree)는 한 노드를 기준으로 왼쪽 서브 트리는 모두 그 노드보다 작은 값을 가지고 있으며, 오른쪽 서브 트리는 모두 그 노드보다 큰 값을 가지고 있는 이진 트리*(binary tree)이다. 수식으로 표현하면 왼쪽 자식 노드의 값 <= 부모 노드의 값 <= 오른쪽 자식 노드의 값이 된다.
*이진 트리(binary tree) : 트리의 차수가 2 이하인 트리
연산
이진 탐색 트리의 연산은 트리의 형태에 따라 시간 복잡도가 달라진다. 트리가 균형잡혀 있다면 모든 연산이 O(logN)이지만, 편향*되어 있다면 O(N)에 가까워진다.
신장 트리
신장 트리(spanning tree)는 정점이 n개인 그래프에서 최소 개수의 간선으로 모든 정점을 연결한 트리 형태의 부분 그래프를 의미한다. 신장 트리는 도로를 최소화 해 모든 도시를 연결해야 하는 도로망 건설이나 네트워크 선을 최소로 사용해 시스템을 연결해야 하는 통신망 설계 등과 같은 곳에 사용될 수 있다.
그래프에서 순회를 하면 n - 1개의 간선을 이동하면서 모든 정점을 방문하게 되므로 순회 경로는 신장 트리가 된다. DFS를 이용해 생성된 신장 트리를 깊이 우선 신장 트리(depth first spanning tree), BFS를 이용해 생성된 신장 트리를 너비 우선 신장 트리(breadth first spanning tree)라 한다.
최소 비용 신장 트리
신장 트리 중 가중치의 합이 최소인 신장 트리를 최소 비용 신장 트리(minimum cost spanning tree)라 한다. 최소 비용 신장 트리를 만드는 방법으로 크루스칼 알고리즘과 프림 알고리즘이 있다.
크루스칼 알고리즘
크루스칼 알고리즘은 가중치가 낮은 간선을 삽입하면서 MST를 만드는 것이다.
힙
힙(heap)은 완전 이진 트리에 있는 노드 중에서 키값이 가장 큰 노드나 키값이 가장 작은 노드를 찾기 위해 만든 자료구조다. 키값이 가장 큰 노드를 찾기 위한 힙을 최대 힙(max heap), 가장 작은 노드를 찾기 위한 힙을 최소 힙(min heap)이라고 한다. 우선순위 큐(priority queue)라고도 한다. STL에서는 std::priority_queue로 구현이 되어 있다.
힙의 불변성
힙은 최대 / 최소 원소에 즉각적으로 접근이 가능해야 한다. 따라서 최대 / 최소 원소가 항상 고정된 위치에 있어야 한다. 그래서 최대 / 최소 원소는 항상 트리의 루트에 존재한다. 또, 부모 노드가 두 자식 노드보다 항상 크거나 작아야 한다.
연산
- 검색 및 읽기
- 삽입
- 삭제
해시 테이블
크기상관없이 고정된길이의 출력값으로 바뀜
- 해싱(hashing) : 입력의 크기에 상관 없이 일정 크기의 값으로 변환하는 것. 이에 사용되는 함수를 해시 함수(hash function)라 한다.
- 해시 테이블(hash table) : 해싱을 활용해 데이터를 저장하는 검색을 위한 자료구조. 연관 배열(associative array)이라고도 한다. 해시 값을 테이블의 인덱스로 활용한다.
- 충돌 처리
- 백트래킹
- 상태공간트리
- 찾는 해를 포함하는 트리
- 즉, 해가 존재한다면 그것은 반드시 이 트리의 어떤 한 노드에 해당함. 따라서 이 트리를 체계적으로 탐색하면 해를 구할 수 있음
- 상태공간 트리의 모든 노드를 탐색해야 하는 것은 아니다.
- 루트에서 출발하여 체계적으로 모든 노드를 방문하는 절차를 기술한다.
- 상태공간 트리를 DFS로 탐색하여 해를 찾는 알고리즘
- 멱집합
해시 테이블
- 연관 배열
- 키와 값의 쌍으로 이뤄진 리스트
- 해싱(hashing) : 문자를 가져와 숫자로 변환하는 과정.
- 해시 함수(hash function) : 글자를 특정 숫자로 변환하는 함수
- 충돌
- 효율성에 영향을 미치는 요인 → 많은 메모리를 낭비하지 않으면서 균형을 유지하며 충돌을 피한다.
- 집합에 사용
- 순서를 유지하지 못한다.
정렬
버블정렬
선택정렬
삽입정렬
분할정복법
- 분할 : 해결하고자 하는 문제를 작은 크기의 동일한 문제들로 분할
- 정복 : 각각의 작은 문제를 순환적으로 해결
- 합병 : 작은 문제의 해를 합하여 원래 문제의 대한 해를 구함
- Merge Sort
- 절차
- 데이터가 저장된 배열을 절반으로 나눔
- 각각을 순환적으로 정렬
- 정렬된 두 개의 배열을 합쳐 전체를 정렬
- 시간복잡도 : O(nlogn) / 공간복잡도 : O(n)
퀵 정렬
- 매우 빠른 정렬 방법 중 하나로 평균적인 경우에서 효율적이다.
TO DO : 퀵 정렬 구현 및 퀵 실렉트 구현
# 자료구조 및 알고리즘
- STL : 표준 템플릿 라이브러리.
- 컨테이너 : 자료구조 구현체
- 반복자 : 컨테이너의 요소에 접근할 수 있는 포인터
- 알고리즘 : 반복자를 기반으로 수행되는 절차- 리스트 : 순서가 있는 자료구조
- 선형 리스트 / 단일 연결 리스트, 이중 연결 리스트, 원형 연결 리스트
- 선형 리스트
- 임의 접근이 가능하다.
- 읽기 : O(1) / 삽입, 삭제 : 맨 끝이면 O(1), 처음이나 중간이면 O(N) / 검색 : O(N), 정렬되어 있을 시 이진 검색을 사용해서 O(logN
'자료구조와 알고리즘' 카테고리의 다른 글
| 그래프 (0) | 2022.07.05 |
|---|---|
| 나무(Tree) (0) | 2022.07.04 |
| 자료 구조 리스트(선형리스트,연결리스트) (0) | 2022.06.21 |